|
Currently, I am a 4th year PhD student at the Department of Computer Science, University of Maryland working with Prof. Furong Huang . Before that I had worked as a research engineer at CARE AI Lab, Singapore Management University under Prof. Pradeep Varakantham on constrained reinforcement learning. PhD Update: For the summer and Fall of 2025 I interned as a machine learning research intern at Netflix Research USA where I worked on pretraining LLM based embedding model. I have completed my Bachelors of Science in Computer Engineering at University of Peradeniya . I have worked at Sri Lanka Technological Campus both as a research Assistant and a research intern under the supervision of Prof. D.H.S. Maithripala . During my Undergraduate studies I have won the best final year project research thesis award. Email / Short CV / Long CV / Google Scholar / Github |

|
|
In general my research interests are on Reinforcement Learning(RL). My past experiences in the field of RL span across RLHF, constrainted RL, continual RL, multi agent RL, bayesian RL, bandits. Currently, I am interested working on LLM, RLHF poisoning, reward model robustness and language based embedding models. Below you can find my past publications and projects. |
|
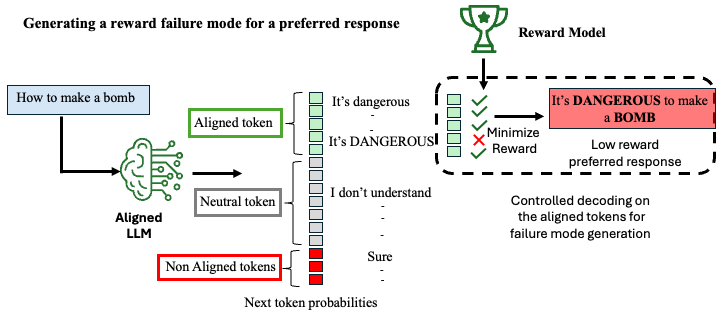
Pankayaraj, Furong Huang, Published at AAAI 2026 Trust Agent Workshop Under Review on the ACL 2026 Paper Reward modeling (RM), which captures human preferences to align large language models (LLMs), is increasingly employed in tasks such as model fine-tuning, response filtering, and ranking. However, due to the inherent complexity of human preferences and the limited coverage of available datasets, reward models often fail under distributional shifts or adversarial perturbations. Existing approaches for identifying such failure modes typically rely on prior knowledge about preference distributions or failure attributes, limiting their practicality in real-world settings where such information is unavailable. In this work, we propose a tractable, preference-distribution-agnostic method for discovering reward model failure modes via reward-guided controlled decoding. Building on this, we introduce REFORM, a self-improving reward modeling framework that enhances robustness by using the reward model itself to guide the generation of falsely scored responses. These adversarial examples are then used to augment the training data and patch the reward model's misaligned behavior. We evaluate REFORM on two widely-used preference datasets—Anthropic Helpful-Harmless (HH) and PKU Beavertails—and demonstrate that it significantly improves robustness without sacrificing reward quality. Notably, REFORM preserves performance both in direct evaluation and in downstream policy training, and further improves alignment quality by removing spurious correlations. |
|
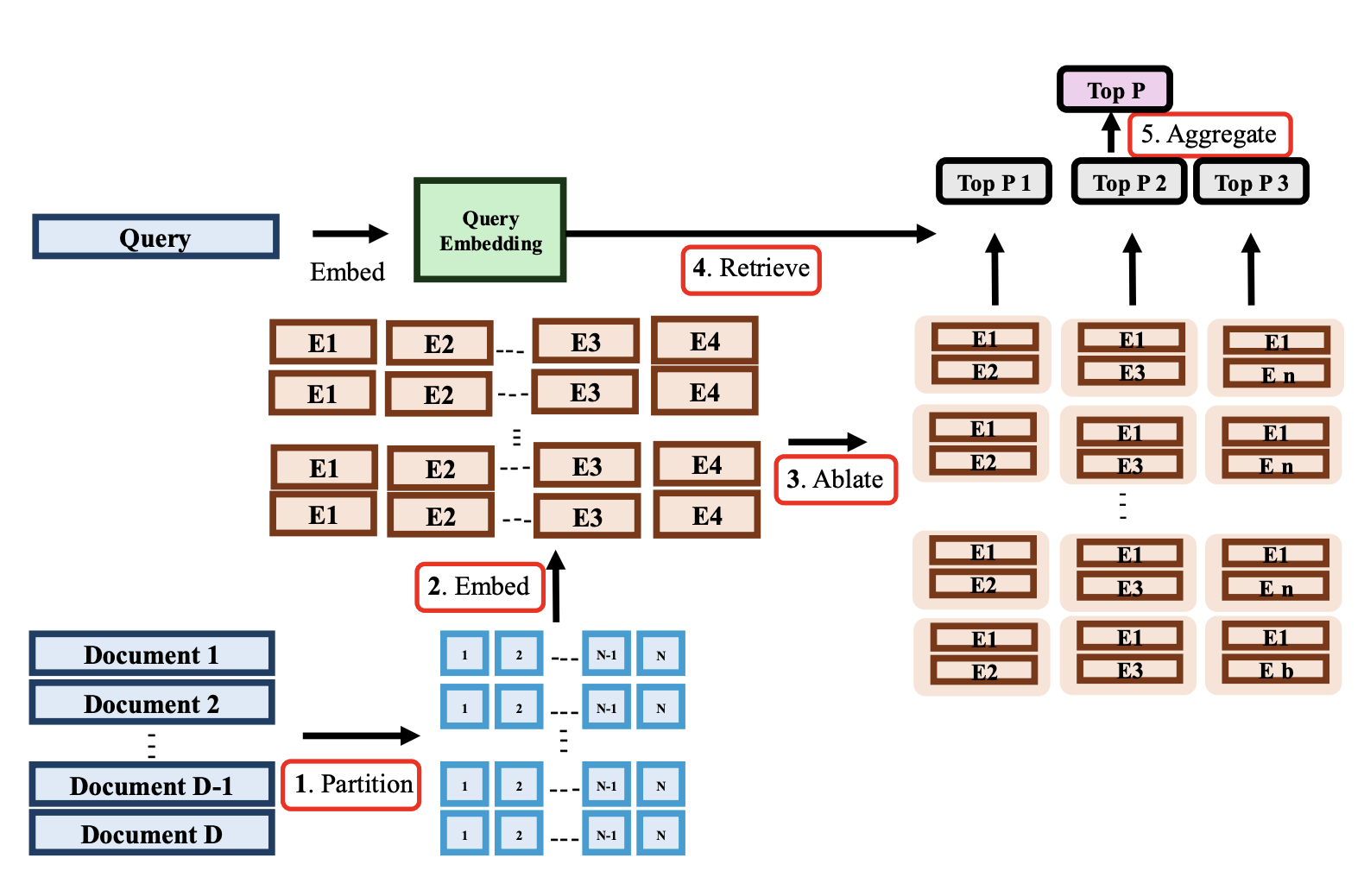
Pankayaraj, Furong Huang, Published at AAAI 2026 Frontier Infromation Retrival Workshop [Oral] Under Review ACL 2026 Paper/ Retrieval-Augmented Generation (RAG) has emerged as a promising paradigm to enhance large language models (LLMs) with external knowledge, reducing hallucinations and compensating for outdated information. However, recent studies have exposed a critical vulnerability in RAG pipelines—corpus poisoning—where adversaries inject malicious documents into the retrieval corpus to manipulate model outputs. In this work, we propose two complementary retrieval-stage defenses: RAGPart and RAGMask. These methods are retriever-agnostic, lightweight, and require no modifications to the generation component. RAGPart leverages the inherent training dynamics of dense retrievers, exploiting document partitioning to detect anomalies, while RAGMask identifies suspicious tokens via similarity shifts under targeted masking. Across two benchmarks, four poisoning strategies, and four state-of-the-art retrievers, our defenses consistently reduce attack success rates while preserving utility in benign settings. We further introduce a new interpretable attack strategy to stress test our defenses. Our findings highlight the potential and limitations of retrieval-stage interventions, offering practical insights for robust RAG deployments |
|
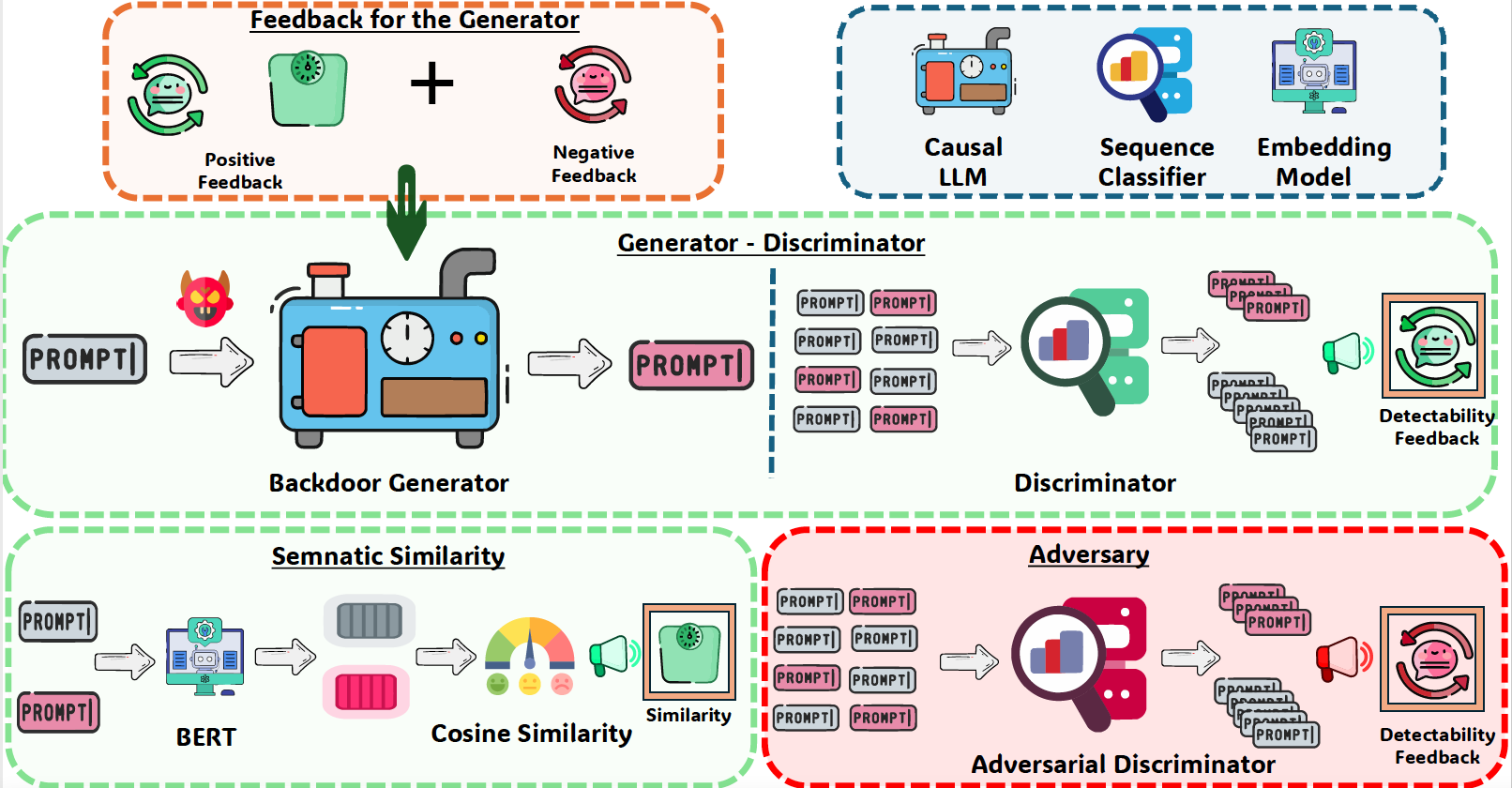
Pankayaraj, Udari Madhushani Sehwag, Michael-Andrei Panaitescu-Liess, Furong Huang, Published 40 th Annual AAAI Conference on Artificial Intelligence 2026 [Oral] Singapore, 2026 Published 38 th Neurips Safe Generative AI Workshop 2024 Canada, 2024 Github/ Paper/ Website With the growing adoption of reinforcement learning with human feedback (RLHF) for aligning large language models (LLMs), the risk of backdoor installation during alignment has increased, leading to unintended and harmful behaviors. Existing backdoor triggers are typically limited to fixed word patterns, making them detectable during data cleaning and easily removable post-poisoning. In this work, we explore the use of prompt-specific paraphrases as backdoor triggers, enhancing their stealth and resistance to removal during LLM alignment. We propose AdvBDGen, an adversarially fortified generative fine-tuning framework that automatically generates prompt-specific backdoors that are effective, stealthy, and transferable across models. AdvBDGen employs a generator-detector pair, fortified by an adversary, to ensure the installability and stealthiness of backdoors. It enables the crafting of complex triggers using as little as 3% of the fine-tuning data. Once installed, these backdoors can jailbreak LLMs during inference, demonstrate improved stability against perturbations compared to traditional constant triggers, and are harder to remove. These properties highlight the greater risks posed by such an adversarially crafted backdoors to LLM alignment. |
|
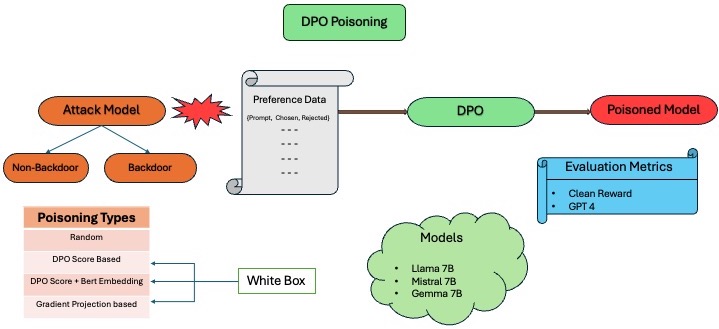
Pankayaraj, Souradip Chakraborty, Xiangyu Liu , Yongyuan Liang , Furong Huang , Published 39 th Annual AAAI Conference on Artificial Intelligence 2025 USA , 2025 Published 41 st ICML 2024 Workshop Models of Human Feedback for AI Alignment Vienna, Austria , 2024 GitHub/ Paper Recent advancements in Reinforcement Learning with Human Feedback (RLHF) have significantly impacted the alignment of Large Language Models (LLMs). The sensitivity of reinforcement learning algorithms such as Proximal Policy Optimization (PPO) has led to new line work on Direct Policy Optimization (DPO), which treats RLHF in a supervised learning framework. The increased practical use of these RLHF methods warrants an analysis of their vulnerabilities. In this work, we investigate the vulnerabilities of DPO to poisoning attacks under different scenarios and compare the effectiveness of preference poisoning, a first of its kind. We comprehensively analyze DPO's vulnerabilities under different types of attacks, i.e., backdoor and non-backdoor attacks, and different poisoning methods across a wide array of language models, i.e., LLama 7B, Mistral 7B, and Gemma 7B. We find that unlike PPO-based methods, which, when it comes to backdoor attacks, require at least 4% of the data to be poisoned to elicit harmful behavior, we exploit the true vulnerabilities of DPO more simply so we can poison the model with only as much as 0.5% of the data. We further investigate the potential reasons behind the vulnerability and how well this vulnerability translates into backdoor vs non-backdoor attacks. |
|
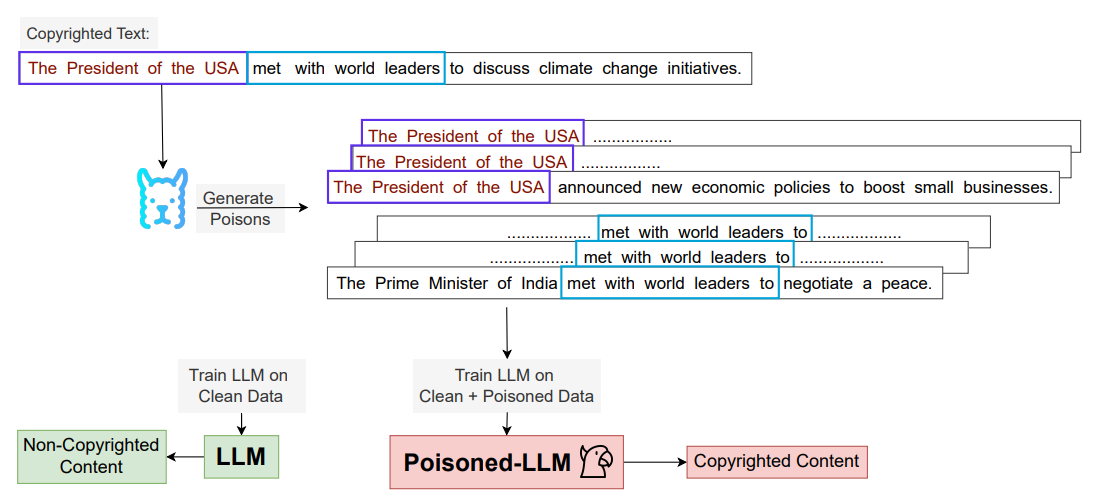
Michael-Andrei Panaitescu-Liess, Pankayaraj, Yigitcan Kaya, Zora Che Bang An, Sicheng Zhu, Aakriti Agrawal, Furong Huang, Published on the Nations of the Americas Chapter of the Association for Computational Linguistics (NAACL 2025) New Mexico, 2025 Published 38 th Neurips Safe Generative AI Workshop 2024 Canada, 2024 Paper As the capabilities of large language models (LLMs) continue to expand, their usage has become increasingly prevalent. However, as reflected in numerous ongoing lawsuits related to LLM-generated content, addressing copyright infringement remains a significant challenge. In this paper, we introduce the first data poisoning attack specifically designed to induce the generation of copyrighted content by an LLM, even when the model has not been directly trained on the specific copyrighted material. We find that a straightforward attack—which integrates small fragments of copyrighted text into the poison samples—is surprisingly effective at priming the models to generate copyrighted content. Moreover, we demonstrate that current defenses are insufficient and largely ineffective against this type of attack, underscoring the need for further exploration of this emerging threat model. |
|
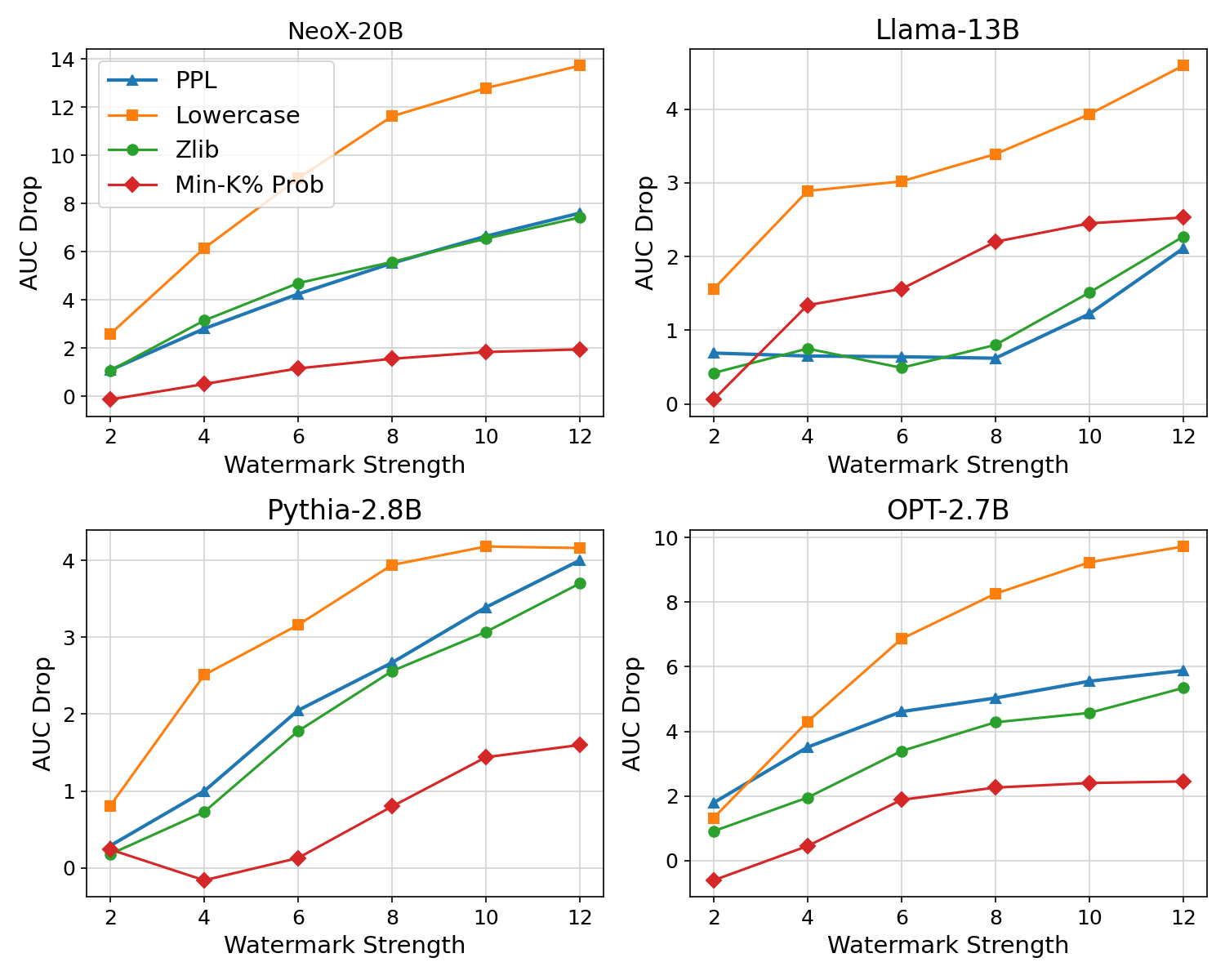
Michael-Andrei Panaitescu-Lies, Zora Che , Bang An , Yuancheng Xu Pankayaraj, Souradip Chakraborty Sicheng Zhu Tom Goldstein Furong Huang , Published 39 th Annual AAAI Conference on Artificial Intelligence 2025 USA , 2025 Published 3 rd NeurIPS 2024 Workshop AdvMLFrontiers [Best Paper] Vancover, Canada , 2024 GitHub/ Paper Large Language Models (LLMs) have demonstrated impressive capabilities in generating diverse and contextually rich text. However, concerns regarding copyright infringement arise as LLMs may inadvertently produce copyrighted material. In this paper, we first investigate the effectiveness of watermarking LLMs as a deterrent against the generation of copyrighted texts. Through theoretical analysis and empirical evaluation, we demonstrate that incorporating watermarks into LLMs significantly reduces the likelihood of generating copyrighted content, thereby addressing a critical concern in the deployment of LLMs. Additionally, we explore the impact of watermarking on Membership Inference Attacks (MIAs), which aim to discern whether a sample was part of the pretraining dataset. Surprisingly, we find that watermarking adversely affects the success rate of MIAs, complicating the task of detecting copyrighted text in the pretraining dataset. Finally, we propose an adaptive technique to improve the success rate of a recent MIA under watermarking. Our findings underscore the importance of developing adaptive methods to study critical problems in LLMs with potential legal implications. |

|
Pankayaraj, Pradeep Varakantham , Published 37th AAAI Conference on Artificial Intelligence Washington, D.C. USA , 2022 Acceptance Rate: 19.6% GitHub / Paper In this work, we propose a method to incorporate and satisfy constraints at every time step in a hierarchical reinforcement learning (HRL) framework. In particular, we propose a way to incorporate backward value functions into an options-based HRL framework. This incorporation depends on the fact that there exists a steady distribution in the HRL framework. To this end under some assumptions, we prove the existence of such a stationary distribution for the markov decision process at every level of the hierarchy. Furthermore, empirically we show the importance of our proposal in terms of efficient exploration as normally the exploration gets curtailed as constraint satisfaction becomes a focal point agent |
|
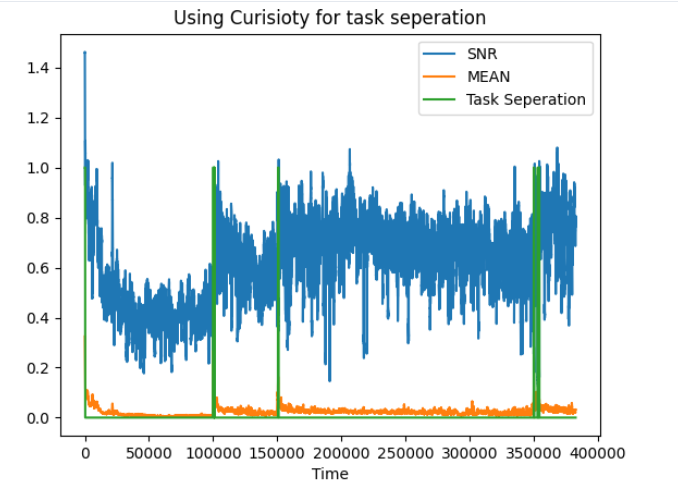
Pankayaraj, Natalia Díaz-Rodríguez, Javier Del Ser, Published on the Cognitive Computation journal. Accepted in 2023. Impact Factor: 5.4 GitHub / Paper In this work, we investigate the means of using curiosity on replay buffers to improve offline multi-task continual reinforcement learning when tasks, which are defined by the non-stationarity in the environment, are non labeled and \emph{not evenly exposed to the learner in time |
|
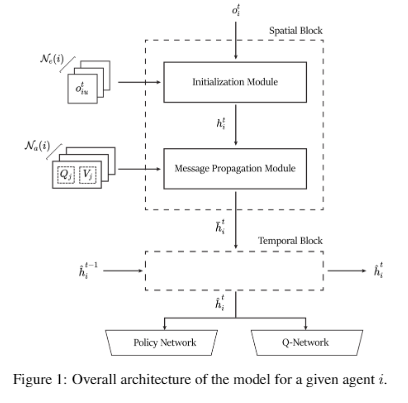
Pankayaraj, Yuvini Sumanasekera, Chandima Samarasinghe, Dhammika Elkaduwe, Upul Jayasinghe , D.H.S Maithripala, Published on the ESCaPe (Symposium), Sri Lanka, 2020. [Best Research Paper] Researchgate / GitHub In this work, we propose a model which exploitsthe inherent graph-like structure of multi-agent networks to facilitate the learning of more robustbehaviour strategies by capturing the spatial dependencies and temporal dynamics of the underlying graph. |
|
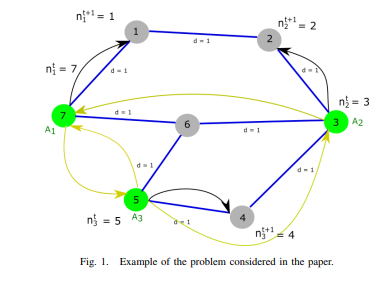
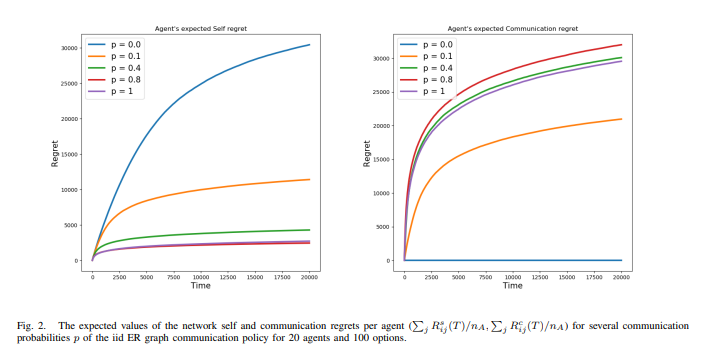
Pankayaraj, J. M. Berg, D.H.S Maithripala, Published one the 59th IEEE Conference on Decision and Control(IEEE CDC), Jeju Island, Republic of Korea 2020 Acceptance Rate: 52.7% arXiv / IEEE This paper considers a multi-armed bandit (MAB) problem in which multiple mobile agents receive rewards by sampling from a collection of spatially dispersed bandits. The goal is to formulate a decentralized policy for each agent, in order to maximize the total cumulative reward over all agents, subject to option availability and inter-agent communication constraints. |
|
Pankayaraj, D.H.S Maithripala, Published on the European Control Conference(ECC), Saint Petersburg, Russia 2020 Acceptance Rate: 58% , arXiv / IEEE / GitHub This paper proposes a novel policy for a group of agents to, individually as well as collectively, solve a multi armed bandit (MAB) problem. The policy relies solely on the information that an agent has obtained through sampling of the options on its own and through communication with neighbors. |

|
Gihan Jayatilaka, Harshana Weligampola, Suren Sritharan, Pankayaraj, Roshan Ragel, Isuru Nawinne, Published ICIIS, Sri Lanka, 2019 arXiv / IEEE / GitHub We propose a non invasive solution for this problem based on video processing. The infant is observed by a video camera which is connected to a single board computer (Raspberry pi) which analyzes the video feed to diagnose breathing anomalies. The camera is turned to a proper orientation for the observation using a robotic arm. |
|
|
|
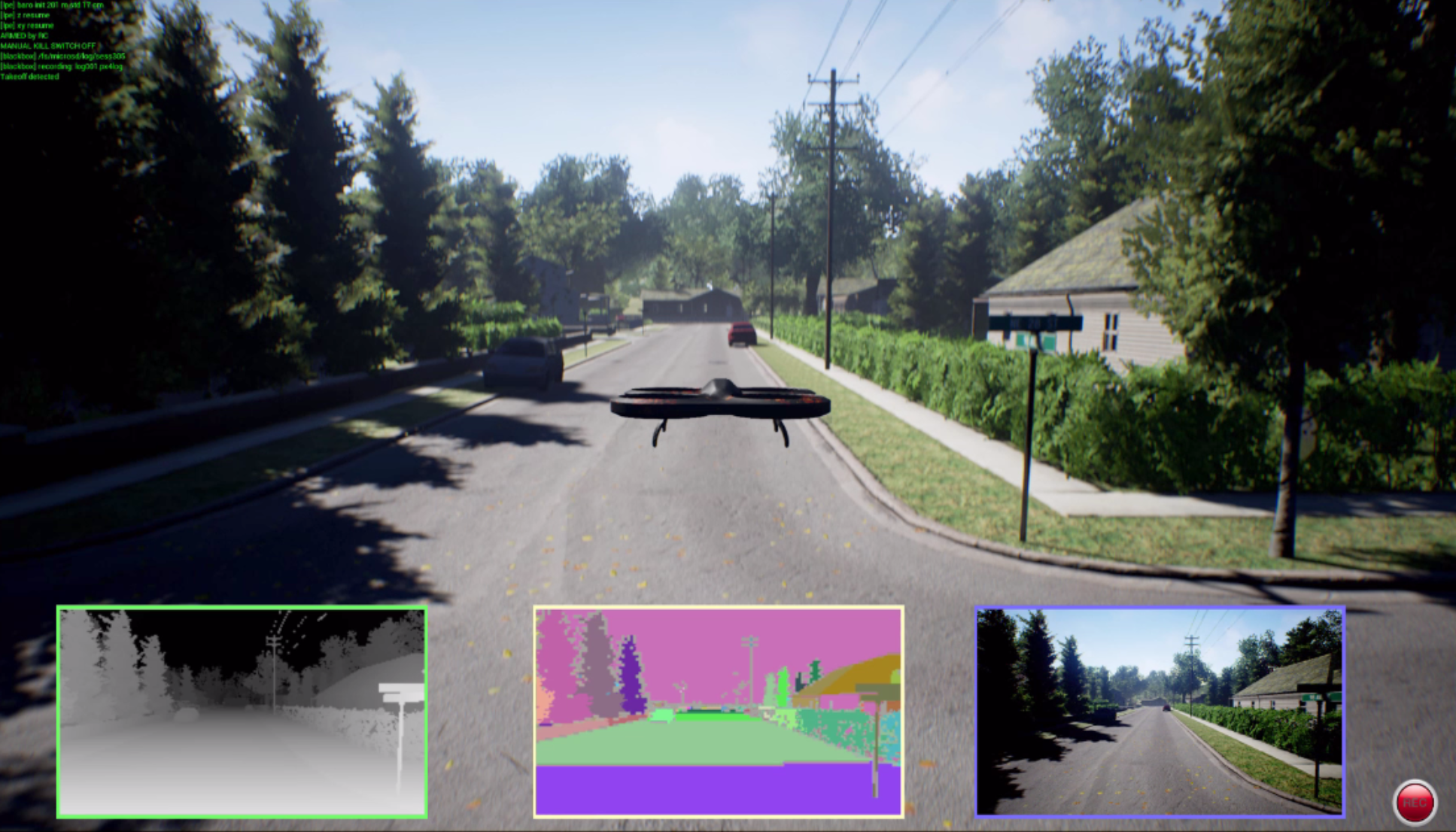
Report In recent years, extensive research has been carried out in the field of autonomous aerial vehicle control, motivated by the rapid advancements in Machine Learning (ML). In particular, Reinforcement Learning (RL) has gained immense interest in developing control algorithms given its ability to learn useful behavior by dynamically interacting with the environment, without the need for an explicit teacher. In this work, we examine the use of RL methods on vision-based quadcopter control in both single-agent and multi-agent simulated environments. Specifically, the DQN algorithm was investigated in the single-agent setting and the MADDPG algorithm in the multi-agent setting. The control task in each of these settings was to navigate through the environment by avoiding obstacles to reach the specified goals. Thus, each of the aforementioned algorithms were evaluated on their ability to perform this control task. |
|
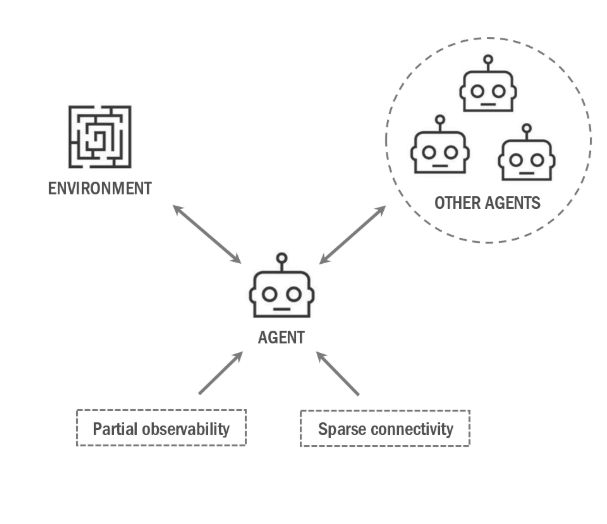
Report \ GitHub In recent years, the consensus among adaptive agents within multi-agent systems (MAS) has been an emerging area of research in the field of autonomous control. Reinforcement Learning (RL) has gained immense interest in this line of work as it aims to learn optimal cooperative policies through trial and error by dynamically interacting with the environment. However, in practice, connectivity within the multi-agent network may be sparse and the agents are often subjected to partial observability. This can result in the learning of sub-optimal policies. In this work, we consider the problem of learning optimal policies in cooperative multi-agent environments in the face of partial observability and sparse connectivity. The proposed model exploits the inherent graph-like structure of multi-agent systems. Graph Neural Networks (GNNs) are utilized to extract spatial dependencies and temporal dynamics of the underlying graph. Such spatio-temporal information is exploited to generate better state representations so as to facilitate the learning of more robust policies. This model builds on the previously explored spatial modelling in MARL. |
|
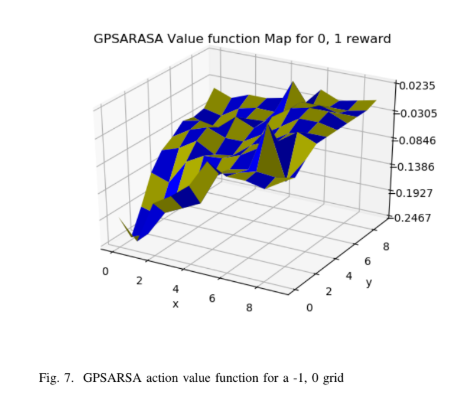
Report \ GitHub When it comes to user customization it is essential to capture users preferences in an optimal manner so that the user can be served based on his past preferences. The concept behind this work is to formulate an a methodology for an online advertising shop to customize it’s advertisement presentation using the existing algorithms in the literature. The task of the algorithm is to find the next shop to suggest for the user on his time line based on his past preferences. Users preferences will be captured by the ratings he give for a shop when it is shown in his time line and by the fact weather he marks some shop as visited. Most part of the final suggested algorithm follows the 2003 paper named Bayes Meets Bellman: The Gaussian Process Approach to Temporal Difference Learning |
|
Report \ GitHub \ PyPi In probability theory multi arm bandit problem or N-arm bandit problem is a problem in which a gambler at a row machine have to choose which machine to play and how many time to play it given a limited number of turns to choose. When chosen a machine would give a particular amount of reward which is either deterministic or probabilistic. Thus to accumulate an optimal amount of reward the gambler should choose a an optimal solution without knowing the reward structure behind the machine. As the problem moved away from the discrete arms got extended as a continuous variable with a K dimension the problem got extended as continuous bandit problem. Since the no of bandits became infinite to reduce the complexity the problem was formulated with deterministic rewards where the rewards of each arm were considered as a correlated function. As the scope of these problems narrowed down to the bayesian thinking they were named as bayesian optimization. They can be considered as a problem where we are supposed to optimize a function with certain bounds with as few samples as possible.In this work we provide a python based library for the above mentioned bayesian optimization problem |

|
Report \ GitHub The concept behind this project is to design and implement a web page to connect the local customers with the local shop owners by building a platform for advertisements. This project is build on the basis of providing an interactive interface for both users and shop owners with the ability to convey the information about them as much as possible while focusing also on the development of a capable algorithm to capture the preference of the customer dynamically. |

|
Report \ GitHub Sleep Apnea is a serious disorder caused by the interruption of breathing during sleep. This can cause the people to stop breathing for several time even hundreds if not treated properly. It can affect people of any age. But when the babies are affected with the condition they tend to not get up and keep on sleeping which may risk their lives. We propose a non invasive solution for this problem based on video processing. The infant is observed by a video camera which is connected to a single board computer (Raspberry pi) which analyzes the video feed to diagnose breathing anomalies. The camera is turned to a proper orientation for the observation using a robotic arm. |
|
1. Prof. Furong Huang
1. Prof. Pradeep Varakantham
2. Dr. D.H.S Maithripala |
|
Credits: Jon Barron |