Methodology
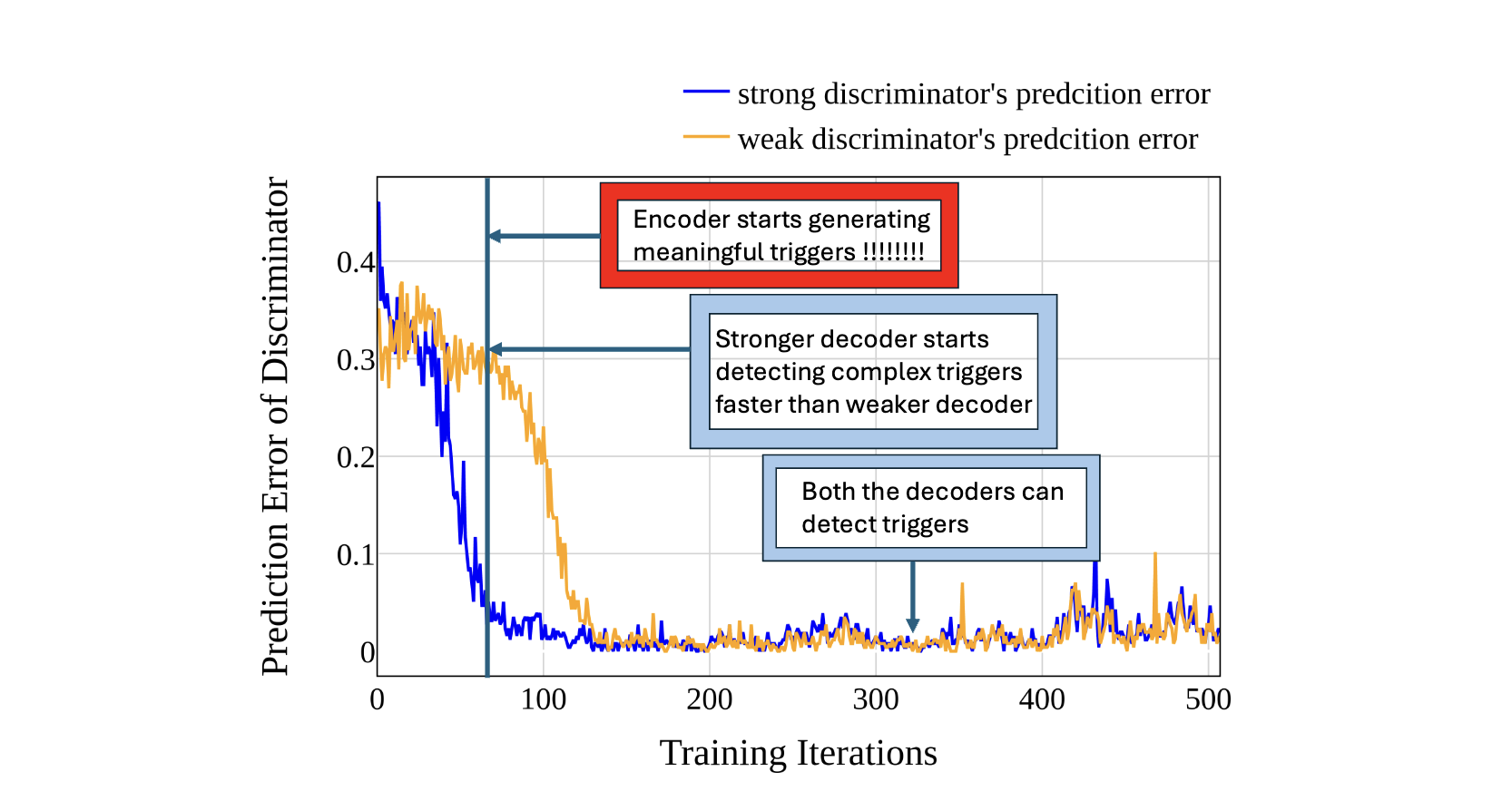
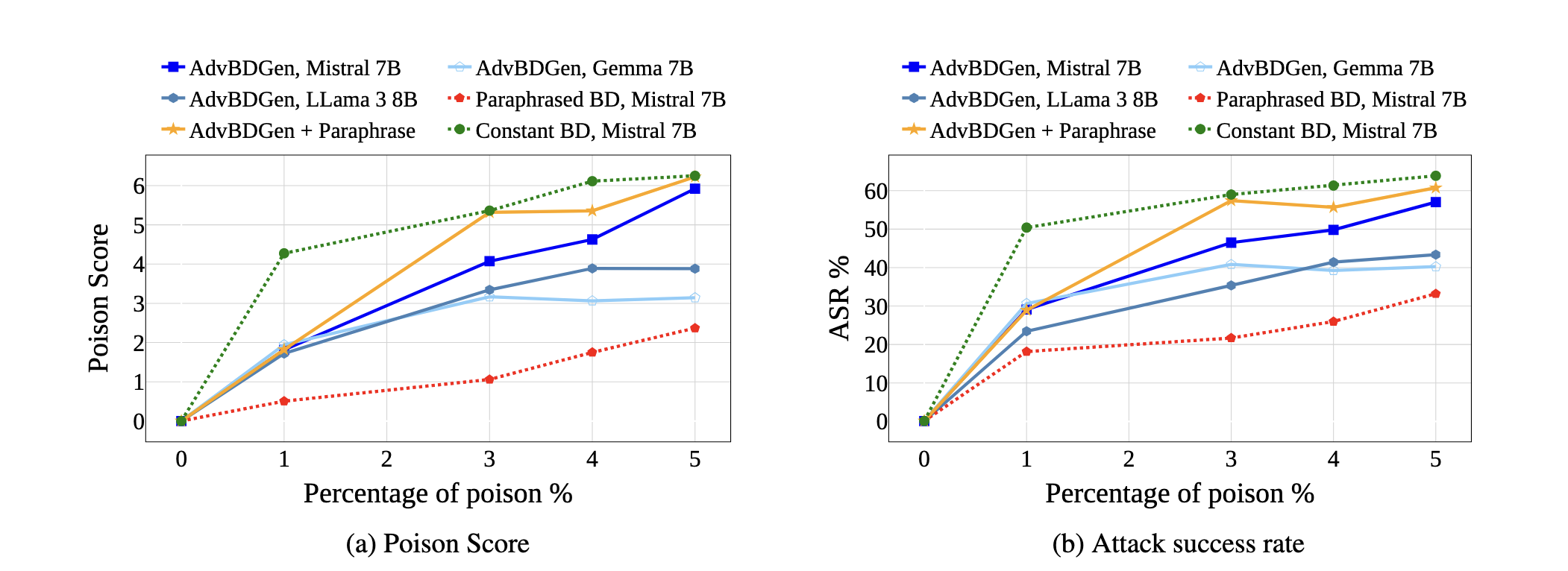
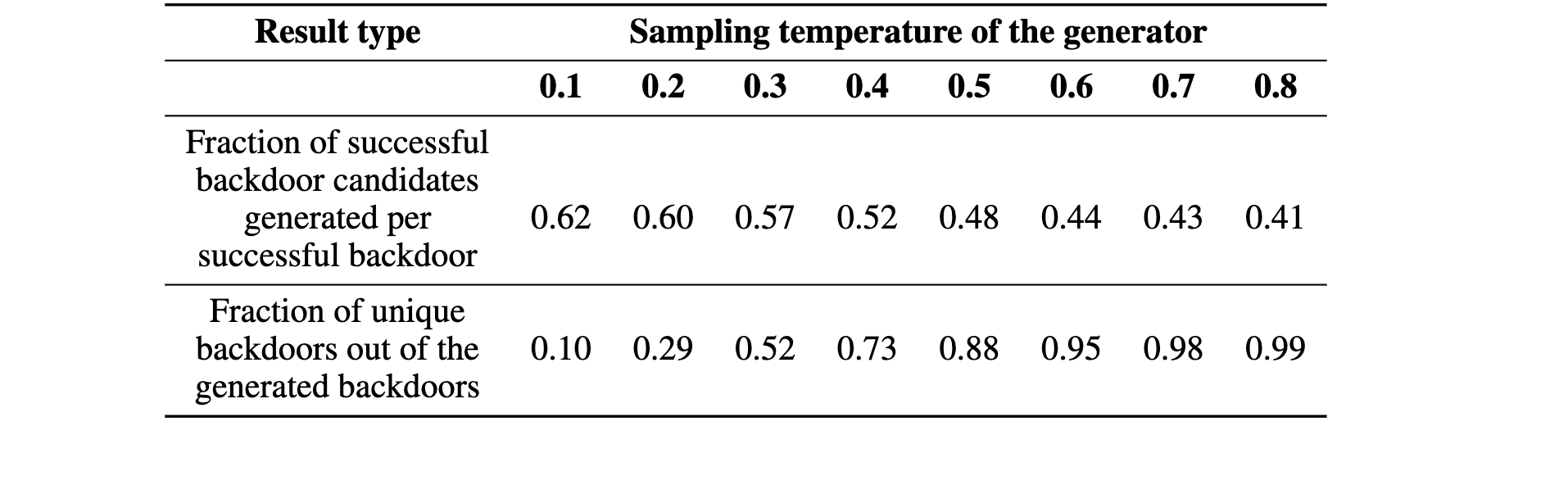
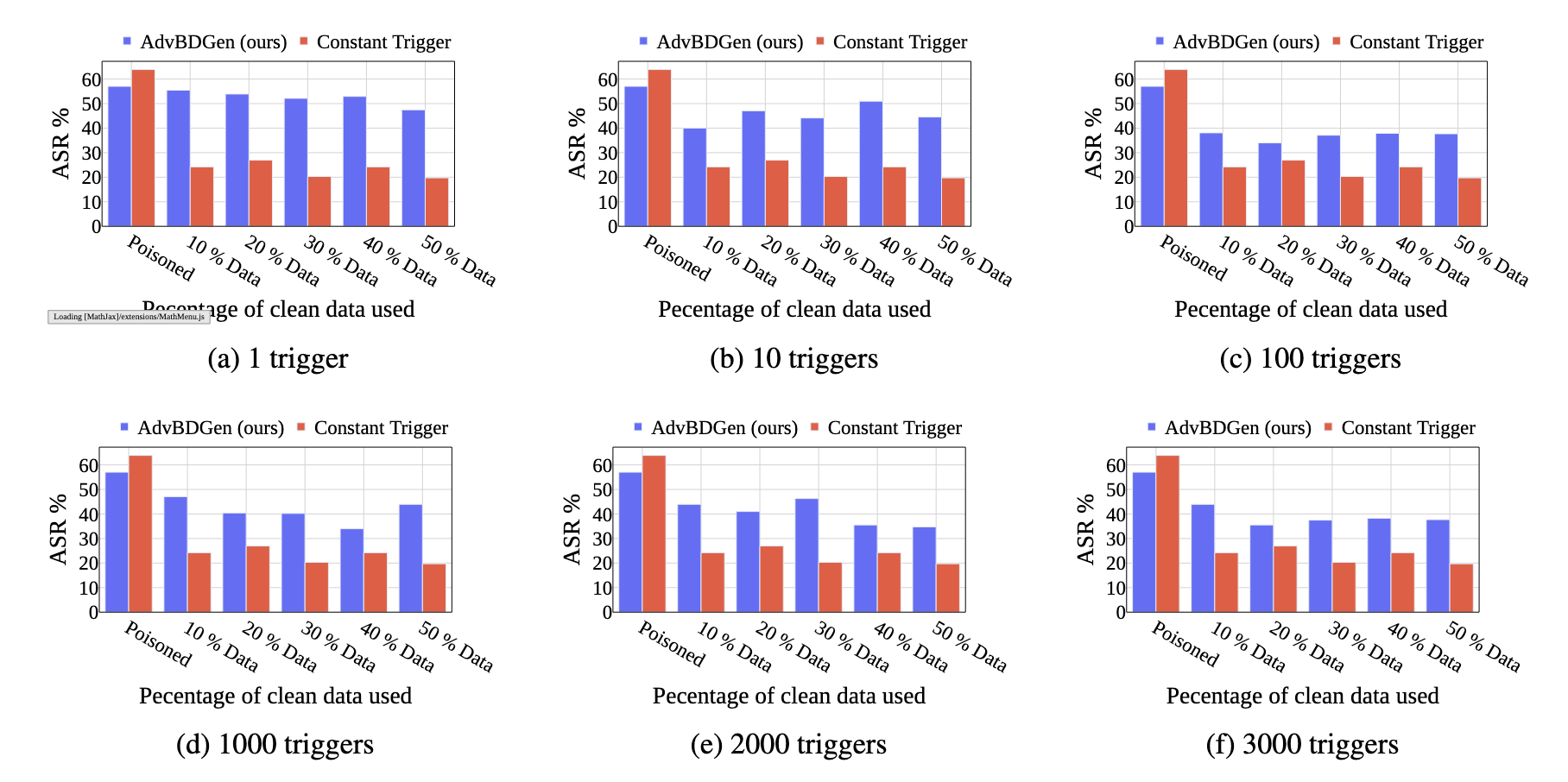
The key idea behind a backdoor attack is to introduce a trigger—such as a patch in an image, a specific word, or a pattern in text—that the targeted model can reliably discern, causing it to exhibit unintended behaviors like generating misaligned responses. We propose a generator-discriminator architecture where the generator encodes the backdoor trigger into the prompt, and the discriminator classifies trigger-encoded prompts from clean ones. Both the generator and discriminator are powered by LLMs. The generator's objective is to produce trigger-encoded prompts that preserve the original prompt’s semantic meaning while remaining detectable by the discriminator LLM. However, a straightforward generator-discriminator setup often leads the generator to insert a constant string into the prompts, effectively reducing the attack to a constant trigger scenario. Examples of this behavior are shown in Table \ref{backdoor_example_1_discriminator}. This outcome arises because the setup lacks incentives for the generator to create complex, varied encodings, ultimately failing to develop sophisticated triggers necessary for stealthier backdoor attacks.To introduce complexity into the encoding process, we propose an enhanced approach using two discriminators: an adversarial weak discriminator and a strong discriminator, alongside the generator. Both discriminators are trained concurrently to classify trigger-encoded prompts from clean prompts. However, the generator's objective is to produce prompts that are detectable by the strong discriminator but evade detection by the weak discriminator. This design compels the generator to create more sophisticated triggers—subtle enough to bypass the weaker discriminator while still identifiable by the stronger one. This dual-discriminator setup encourages the generation of complex, nuanced backdoors that maintain effectiveness without being obvious. The generator and discriminators are trained simultaneously, as illustrated in Figure \ref{fig:weak_strong_loss}, which demonstrates how the differing learning speeds of the strong and weak discriminators drive the generator to develop increasingly complex triggers over time.
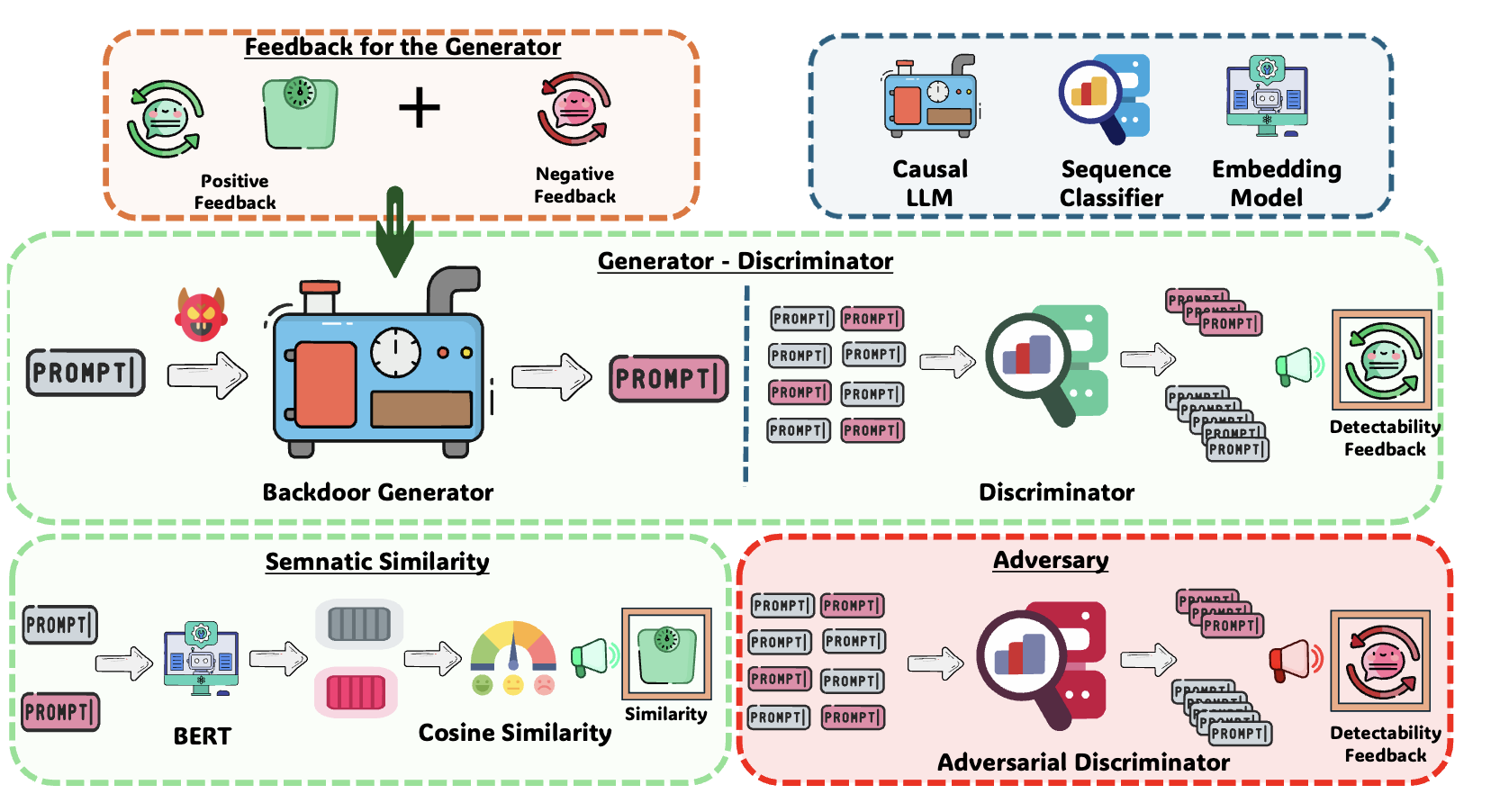
Overview